지수 2.0이 진짜 최적일까: 1.83이 어디서 왔는지, 그리고 오버피팅의 첫 맛
지난 글의 마지막에 이런 의문을 남겼다.
2.0이 진짜 최적의 지수일까? 데이터에서 직접 찾아볼 수 있을까?
빌 제임스는 RS² / (RS² + RA²) 라는 공식을 썼고, 우리는 그게 5시즌 데이터에 잘 들어맞는다는 걸 봤다. 그런데 왜 하필 제곱인가? 빌 제임스 본인도 "유도한 게 아니라 잘 맞아서 썼다"고 인정했다. 어떤 사람들은 야구 분석에서 1.83 을 쓴다. 누가 맞나?
이번 글의 한 줄 요약은 이렇다.
2.0은 살짝 과한 편이고, 1.83은 합리적이고, 우리 5시즌으로는 1.71이 최적이다. 그런데 그 차이는 시즌당 0.1승 안팎이라 실용적으로는 거의 의미가 없다 — 그리고 그게 이 글에서 가장 중요한 이야기다.
지수는 우리가 선택할 수 있는 숫자다
여기서 잠깐 개념을 하나 정리하고 가자. 피타고라스 기댓값 공식을 일반화하면 이렇게 쓸 수 있다.
빌 제임스는 k = 2 로 두었지만, 이 k 는 어디서 정해진 게 아니다. 우리가 고를 수 있다. 데이터 분석에서 이렇게 모델 안에서 우리가 직접 정해주는 숫자를 하이퍼파라미터(hyperparameter) 라고 부른다. "공식의 모양은 정해뒀고, 그 안의 숫자 하나만 우리가 튜닝하는" 자리다.
기계학습으로 가면 이게 학습률, 규제 강도, 트리 깊이 같은 이름으로 우글거리는데, 본질은 같다. 누가 정해주지 않은 자유도, 그래서 우리가 데이터를 보고 결정해야 할 자리.
그래서 자연스러운 다음 질문이 이거다. k 를 1.5부터 2.5까지 0.01 간격으로 바꿔가면서, 어느 값이 실제 승률을 가장 잘 맞추는지 직접 확인해보자.
무엇을 "잘 맞춘다"고 할 것인가
지난 글에서 이미 답을 골라뒀다. MAE — 평균 절대 오차 (Mean Absolute Error).
각 팀의 실제 승률과 피타고라스 예측 승률 차이의 절댓값을 평균낸 값이다. 162경기 시즌으로 환산하면 "예측이 평균적으로 몇 승만큼 빗나가는지" 가 된다.
지난 글에서 r 대신 MAE를 본 이유와 같다. r은 0.95에서 0.9511로 가는 식이라 좁은 폭 안에서만 움직이지만, MAE는 "지금 시즌당 3.5승 빗나가던 게 3.0승으로 줄었나?" 같은 질문에 직설적으로 답해준다.
이번처럼 여러 모델 중에 어느 게 더 잘 맞나 를 비교할 때는 MAE 같은 오차 지표가 r 보다 깔끔하다.
곡선이 그려진다
k = 1.50부터 2.50까지 0.01 간격으로 101개 값을 모두 시험했다. 각 k 마다 5시즌 150팀 전체에서 MAE를 계산하고, k 를 X축에, MAE를 Y축에 두면 다음 곡선이 나온다.
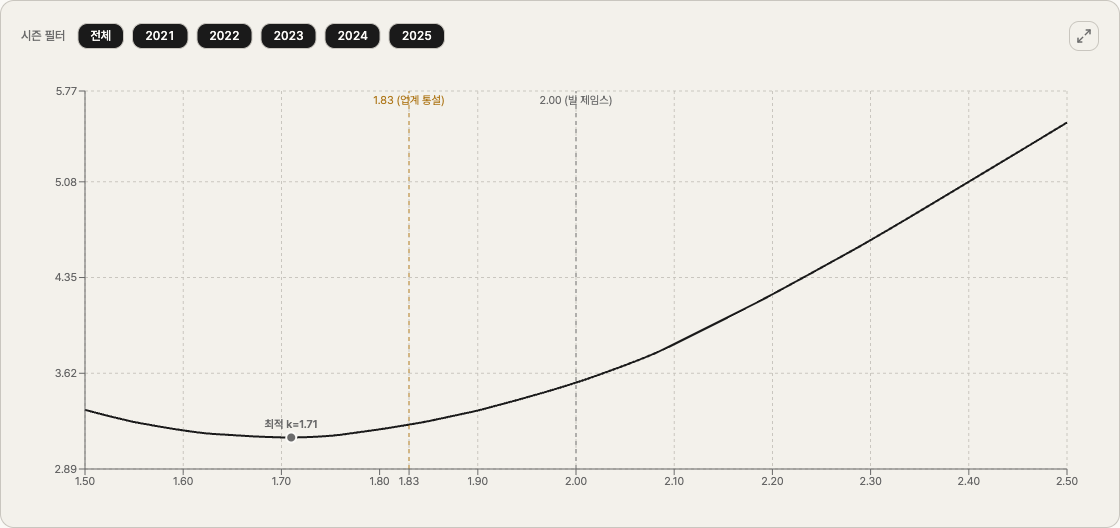
곡선 모양이 명확하다. 왼쪽에서 떨어졌다가 어느 지점에서 바닥을 찍고, 다시 오른쪽으로 올라간다. 위로 볼록한 U자다.
이 U자의 가장 낮은 점이 우리 데이터가 말하는 최적 지수 다. 그 위치는 k = 1.71.
이 k 에서 MAE는 0.01932, 즉 시즌당 약 3.13승 만큼 빗나간다. 빌 제임스의 2.00 으로 계산했을 때 3.55승, 업계가 자주 쓰는 1.83 으로 계산했을 때 3.23승이었다. 비교하면 이렇다.

| 지수 | MAE (승) | 최적 대비 |
|---|---|---|
| 데이터 최적 1.71 | 3.13 | — |
| 업계 통설 1.83 | 3.23 | +0.10승 |
| 빌 제임스 2.00 | 3.55 | +0.42승 |
수치만 놓고 보면 "1.71이 최적이고 2.00은 0.42승 더 빗나간다"고 말할 수 있다. 그런데 0.42승이라는 게 시즌당 한 팀의 평균 오차에서 0.42승만큼 더 벌어진다는 뜻이다. 162경기에서 0.4승 차이는 거의 잡음 수준이다.
1.83 vs 1.71 의 0.10승 차이는 더 작다. 사실상 같은 값으로 봐도 무방하다.
1.83이 어디서 왔냐면
여기서 잠깐 이야기 하나. 1.83이 어디서 나온 숫자인지가 의외로 재밌다.
이걸 발견한 사람은 대릴 모리(Daryl Morey) 다. 농구 팬이라면 "휴스턴 로키츠 단장" 이나 "필라델피아 76ers 사장" 으로 기억할 텐데, 이 사람은 농구로 가기 전 야구 통계 분석을 했다. 1990년대 후반, 빌 제임스가 k = 2 를 쓰는 걸 보고 "왜 굳이 2여야 하지?" 라고 질문했다. 그래서 더 긴 역사 데이터(1900년대 초반부터)를 가지고 같은 종류의 스윕을 돌렸고, 1.83 근처에서 MAE가 최소가 된다는 걸 발견했다.
이후 베이스볼 레퍼런스(Baseball Reference) 같은 주요 통계 사이트는 빌 제임스의 2 대신 모리의 1.83을 표준으로 채택했다. 즉 1.83 은 누군가 머리에서 뽑은 숫자가 아니라, 이번 글에서 우리가 한 작업과 똑같은 작업을 더 큰 데이터로 한 결과다.
그래서 우리 5시즌에서 나온 1.71 도 그 자체로 새로운 발견은 아니다. 데이터 표본을 바꿀 때마다 최적값은 조금씩 흔들린다. 모리의 1.83 은 100년 가까운 데이터에서, 우리의 1.71 은 5시즌에서 나왔을 뿐이다.
여기서 다음 의심이 자연스럽게 따라온다.
그러면 시즌 하나만 뗐을 때의 최적은 어떻게 흔들릴까?
시즌 하나로만 보면 — 1.57 부터 1.76 까지
5시즌 묶어서 본 게 1.71 이라면, 시즌 하나 (30팀) 만 떼서 같은 스윕을 다시 돌리면 어떻게 될까?
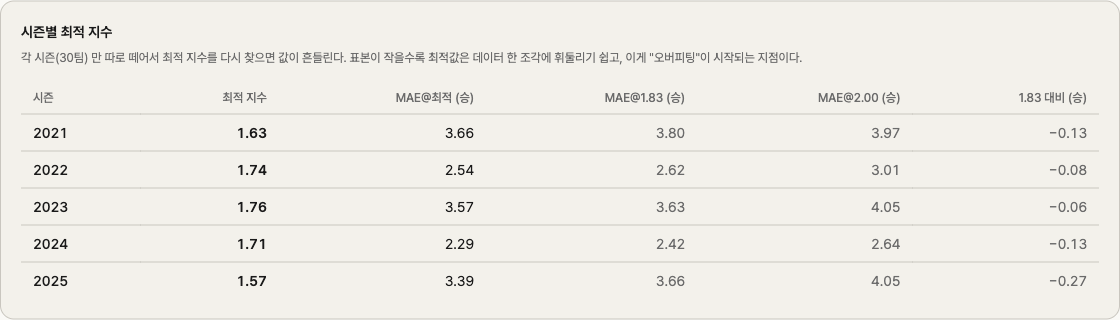
| 시즌 | 최적 k |
|---|---|
| 2021 | 1.63 |
| 2022 | 1.74 |
| 2023 | 1.76 |
| 2024 | 1.71 |
| 2025 | 1.57 |
1.57 부터 1.76 까지 흔들린다. 폭이 0.19다. 평균은 1.68 근처고, 5시즌 합쳐서 본 1.71 이 그 평균의 자연스러운 수렴점이다.
왜 시즌마다 다른가? 시즌 한 번에 30팀이다. 30개 데이터 점이라는 건 통계적으로 작은 표본이다. 그 안의 우연 — 누가 한 점차 승부를 유난히 많이 이겼는지, 누가 8월에 잠깐 부진했다 9월에 회복했는지 같은 게 — 그 시즌의 "최적 지수" 를 좌우한다.
이게 데이터 분석에서 처음 만나는 한 개념의 작은 사례다. 오버피팅(overfitting).
오버피팅 — 모델이 "외워버리는" 순간
오버피팅을 한 줄로 설명하면 이렇다.
모델이 데이터의 진짜 패턴이 아니라, 그 데이터의 우연까지 외워버린 상태.
각 시즌의 최적 k 를 구하면 그 시즌만큼은 MAE가 가장 작아진다. 2025 시즌에 k = 1.57을 쓰면 2025 시즌의 30팀에 대해서는 가장 잘 맞는다. 하지만 그 1.57을 가지고 2024 시즌을 예측하면? 아마 2024의 자기 최적값 1.71 보다 못한다. 1.57 은 2025 의 우연을 외워버린 값이고, 그 우연은 다음 시즌에 반복되지 않는다.
데이터 분석에서 이런 함정은 도처에 있다.
- 어떤 종목 매출 데이터에서 "12개의 변수를 다 넣어 모델을 만들었더니 r² = 0.99 가 나왔다" → 작년 매출 외우기에 가까울 수 있다
- 머신러닝에서 학습 데이터 정확도 99.9% 인데 새 데이터에서 60% → 외운 것
- 이번처럼 시즌마다 최적 지수가 다르다는 것 → 그 시즌만 잘 맞춘 결과일 가능성이 높다
오버피팅을 피하는 가장 단순한 처방은 "덜 튜닝하기" 다. 우리 시즌별 최적이 1.57~1.76 이라면, 어느 한 값에 못박지 말고 그 범위 어딘가의 무난한 값을 쓰면 된다. 1.83 이 정확히 그 자리다. 우리 5시즌으로 보면 살짝 위쪽으로 쏠려 있지만, 더 긴 역사 데이터로 보면 그 자리가 안정점이라는 걸 모리가 보여줬다.
튜닝을 끝까지 밀어붙이는 것보다, 무난한 값에 머무르는 게 미래의 데이터에 더 잘 맞을 때가 많다. 이건 직관에 어긋나지만, 데이터 분석을 깊게 하면 할수록 더 자주 마주치는 진실이다.
정리하면
이번 글에서 우리가 한 일을 한 줄로 요약하면 이렇다.
- 피타고라스 공식의 k 를 1.50~2.50 으로 스윕했다
- 우리 5시즌 데이터로는 k = 1.71 이 최적이었다
- 빌 제임스의 2.00 보다 0.42승, 업계 통설 1.83 보다 0.10승 적게 빗나간다
- 시즌마다 최적값이 1.57~1.76 으로 흔들리는 걸 봤다 — 작은 표본의 한계
- 그래서 1.83 이라는 무난한 값이 실제로는 가장 안전한 선택이다 — 오버피팅을 피하는 한 가지 방법
그리고 그 과정에서 우리는 하이퍼파라미터 와 오버피팅 이라는 두 개념을 처음 만났다. 둘 다 데이터 분석에서 끝까지 따라다닐 친구들이다.
다음으로 가는 다리
지난 글 끝에 이런 말을 남겼다.
잔차가 +0.091 이 모두 운은 아니다. 일부는 실력이고 일부는 운이다. 그걸 어떻게 구별하지?
직접 답하기는 어렵지만, 다음 시즌으로 넘어가서 보면 단서가 나온다. 진짜 운 좋은 시즌이었다면, 다음 해엔 회귀할 것이다. 그게 실력이라면, 다음 해에도 같은 방향으로 나타날 것이다.
2021년 +14.8승 운 좋았던 매리너스는 2022년에 어떻게 됐을까? 2023년 −11승 불운했던 파드리스는 2024년에 회복했을까?
다음 글의 주제는 평균 회귀(regression to the mean) 다. 이름은 거창하지만, 사실 누구나 직관적으로 알고 있는 현상이다. 데이터로 그 직관을 확인하면서, 운과 실력을 어떻게 구별할 수 있는지 같이 본다.
이 분석은 직접 만든 just-mlb 의 Q3 페이지에서 확인할 수 있다. MAE 곡선과 시즌별 최적 지수 표를 직접 만져보면서, 시즌 필터 칩으로 데이터를 한 시즌씩 떼봐도 좋다 — 곡선이 시즌마다 어떻게 흔들리는지가 한눈에 보인다.